Що цікавого дає OpenAI (окрім чатбота та DALL·E)

За останні тижні кількість матеріалів та обговорень про ChatGPT максимально зашкалювала, і здавалося б, що вже почали приймати те, що розробників/дизайнерів/письменників/вставте вашу професію ця машина все ще не замінить, і хоч AI поки не вміє поки що роздумувати та генерувати нові сенси, це все ж дуже гарний інструмент.
Цікаво, що в перший день, коли чатбот став доступним українцям, невимушено слухаючи обговорення чатбота абсолютно всюди, я зрозумів, що система обмеження реєстрація по номеру + обмеження по IP з дозволених країн працює надійно, і це було гарним барʼєром для тих же ІТшників.
Окрім чатботів та генераторів зображень, для розробників є багато чого цікавого, тому якщо ви раптом розробник, і ще не дивились – можливо, там знайдете щось цікаве для себе, а я розповім, що я знайшов цікаве для себе.
🎤 Speech to text
Буквально декілька днів тому OpenAI дали інструменти розробникам для розпізнавання тексту (та ще й перекладати його автоматично на іншу мову), і він розпізнає навіть українську! Причому розпізнаються без будь-яких проблем навіть сильно спотворені голоси з шумом або музикою на фоні.
До війни у мене була ідея створити якийсь агрегатор наших подкастів. Я хотів додати там декілька розумних фільтрів, які можна лише при аналізі аудіо створити, але швидкої альтернативи по розпізнаванню так і не знайшов.
Ця розпізнавалка працює на основі моделі Whisper, і за бажанням її можна запустити безплатно у себе на компʼютері. Локально це максимально повільно працює (на одну хвилину йде декілька хвилин), але завдяки оптимізаціям в OpenAI, записи на 10-15 хвилин розпізнаються буквально за пару секунд. Можливо, незабаром ми побачимо щось нове на основі аудіоконтенту – наприклад, рейтинг подкастів по хейтспічу або навіть перевіряти на фейк все, що було сказане в подкасті (Джо Роган, спиш?).
Поки однією з проблем є те, що модель не може визначати, хто розмовляє, тому з діалогами це не працює, тому повноцінно транскрибувати подкаст не можна, але з монологами працює майже ідеально!
Наприклад, один з моїх улюблених подкастів – Культурний трибунал. Це той випадок, що краще їх прослухувати, чим читати (у цьому подкасті прекрасно абсолютно все!), але оскільки тема про розпізнавання, то Whisper прекрасно справляється з цим :)
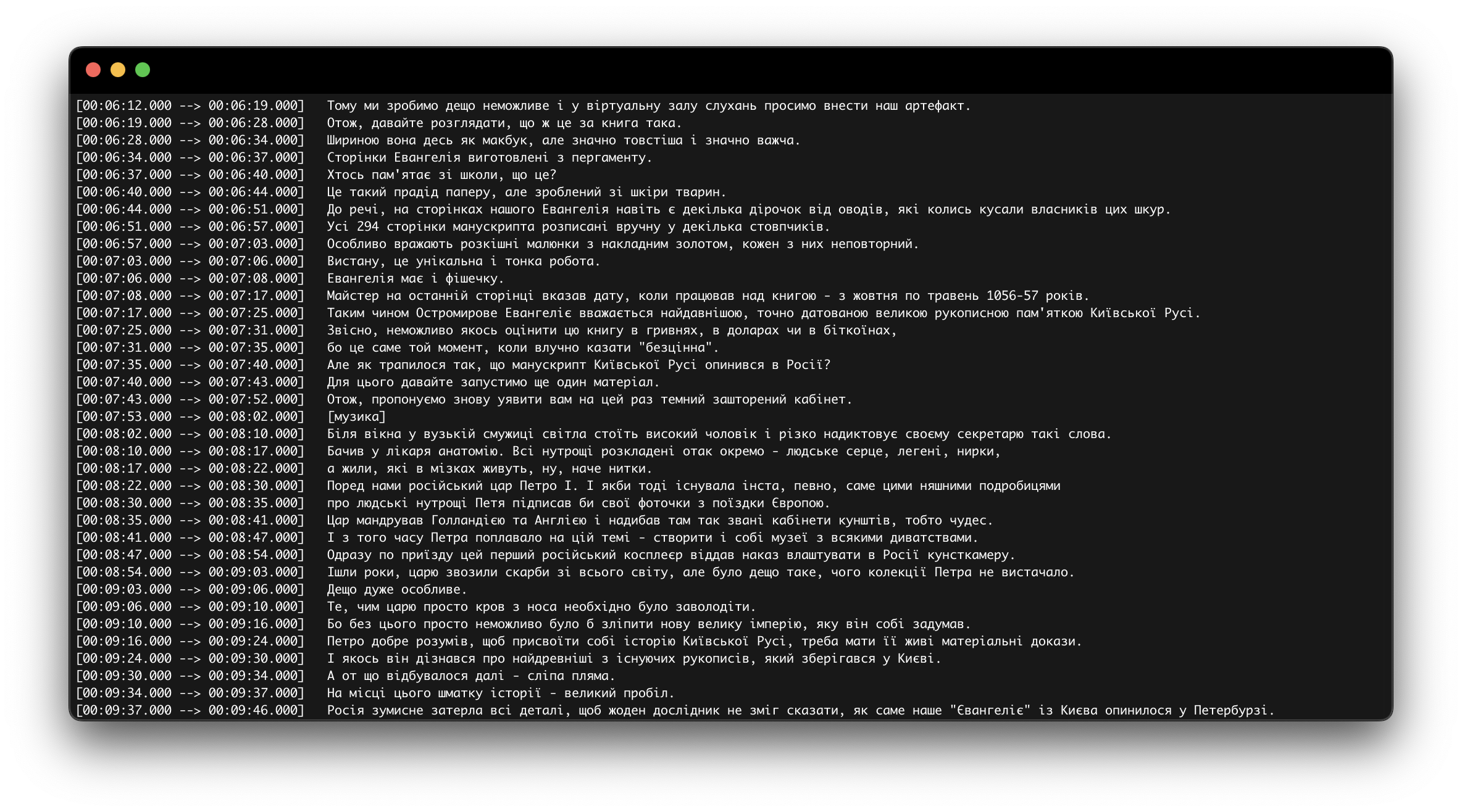
Переклад на англійську, звісно, досить дивний, але най буде тут :)
Передлянути автоматично згенерований переклад
[00:06:12.000 --> 00:06:19.000] So we will do something impossible and ask our artifact to be brought to the virtual hearing room.
[00:06:19.000 --> 00:06:24.000] "Peace Gospel"
[00:06:24.000 --> 00:06:28.000] So let's take a look at what kind of book it is.
[00:06:28.000 --> 00:06:34.000] It is about the width of a MacBook, but much thicker and much heavier.
[00:06:34.000 --> 00:06:37.000] The pages of the Gospel are made of parchment.
[00:06:37.000 --> 00:06:40.000] Does anyone remember what it is from school?
[00:06:40.000 --> 00:06:44.000] This is a kind of paper pradid, but made of animal skin.
[00:06:44.000 --> 00:06:51.000] By the way, there are even a few holes from the sheep on the pages of our Gospel, which once bit the owners of these skins.
[00:06:51.000 --> 00:06:57.000] All 294 pages of the manuscript are hand-painted in several columns.
[00:06:57.000 --> 00:07:03.000] Luxurious paintings with gold plating are especially impressive, each of them is unique.
[00:07:03.000 --> 00:07:06.000] It turns out that this is a unique and delicate work.
[00:07:06.000 --> 00:07:08.000] The Gospel has a trick.
[00:07:08.000 --> 00:07:13.000] The master on the last page said the date when he was working on the book.
[00:07:13.000 --> 00:07:17.000] From October to May 1056-57.
[00:07:17.000 --> 00:07:26.000] Thus, the "Peace Gospel" is considered the oldest, accurately dated, large-handwritten monument of Kievan Rus'.
[00:07:26.000 --> 00:07:31.000] Of course, it is impossible to somehow evaluate this book in hryvnias, dollars or bitcoins,
[00:07:31.000 --> 00:07:35.000] because this is the moment when it is, frankly speaking, priceless.
[00:07:35.000 --> 00:07:40.000] But how did it happen that the manuscript of Kievan Rus' ended up in Russia?
[00:07:40.000 --> 00:07:43.000] Let's launch another material for this.
[00:07:43.000 --> 00:07:52.000] So, we suggest you imagine again a dark, closed-off office.
[00:08:02.000 --> 00:08:10.000] Near the window, in a narrow ray of light, stands a tall man and abruptly dictates such words to his secretary.
[00:08:10.000 --> 00:08:13.000] He saw anatomy in the doctor.
[00:08:13.000 --> 00:08:20.000] All the insides are laid out so separately - human heart, lungs, kidneys, and veins that live in the muscles.
[00:08:20.000 --> 00:08:22.000] Well, like threads.
[00:08:22.000 --> 00:08:25.000] Before us is the Russian Tsar Peter I.
[00:08:25.000 --> 00:08:31.000] And if there was an Insta then, probably with these cute details about human insides,
[00:08:31.000 --> 00:08:35.000] Peter would have signed his photos from a trip to Europe.
[00:08:35.000 --> 00:08:41.000] The Tsar traveled to Holland and England and found there the so-called "art cabinets", that is, miracles.
[00:08:41.000 --> 00:08:47.000] Since then, Peter has been swimming on this topic - to create a museum with all sorts of crafts.
[00:08:47.000 --> 00:08:54.000] Immediately upon arrival, this first Russian cosplayer issued an order to install an art camera in Russia.
[00:08:54.000 --> 00:09:03.000] Years passed, the Tsar was brought gifts from all over the world, but there was something that Peter's collection was not enough for.
[00:09:03.000 --> 00:09:06.000] Something very special.
[00:09:06.000 --> 00:09:10.000] Something that the Tsar just had to possess with blood,
[00:09:10.000 --> 00:09:16.000] because without it it would simply be impossible to sculpt a new great empire that he had conceived.
[00:09:16.000 --> 00:09:24.000] Peter understood well that to assimilate the history of Kievan Rus' you need to have its living and material evidence.
[00:09:24.000 --> 00:09:30.000] And somehow he learned about the oldest of the existing manuscripts, which was kept in Kiev.
[00:09:30.000 --> 00:09:33.000] And here's what happened next - a blind spot.
[00:09:33.000 --> 00:09:36.000] There is a big gap in the place of this piece of history.
[00:09:36.000 --> 00:09:41.000] Russia deliberately erased all the details so that no researcher could say
[00:09:41.000 --> 00:09:45.000] how our Gospel from Kiev ended up in St. Petersburg.
А ось частина епізоду з «Подкаст Підкаст», тому навіть з розмовними форматами все досить круто, але з діалогами поки проблема:
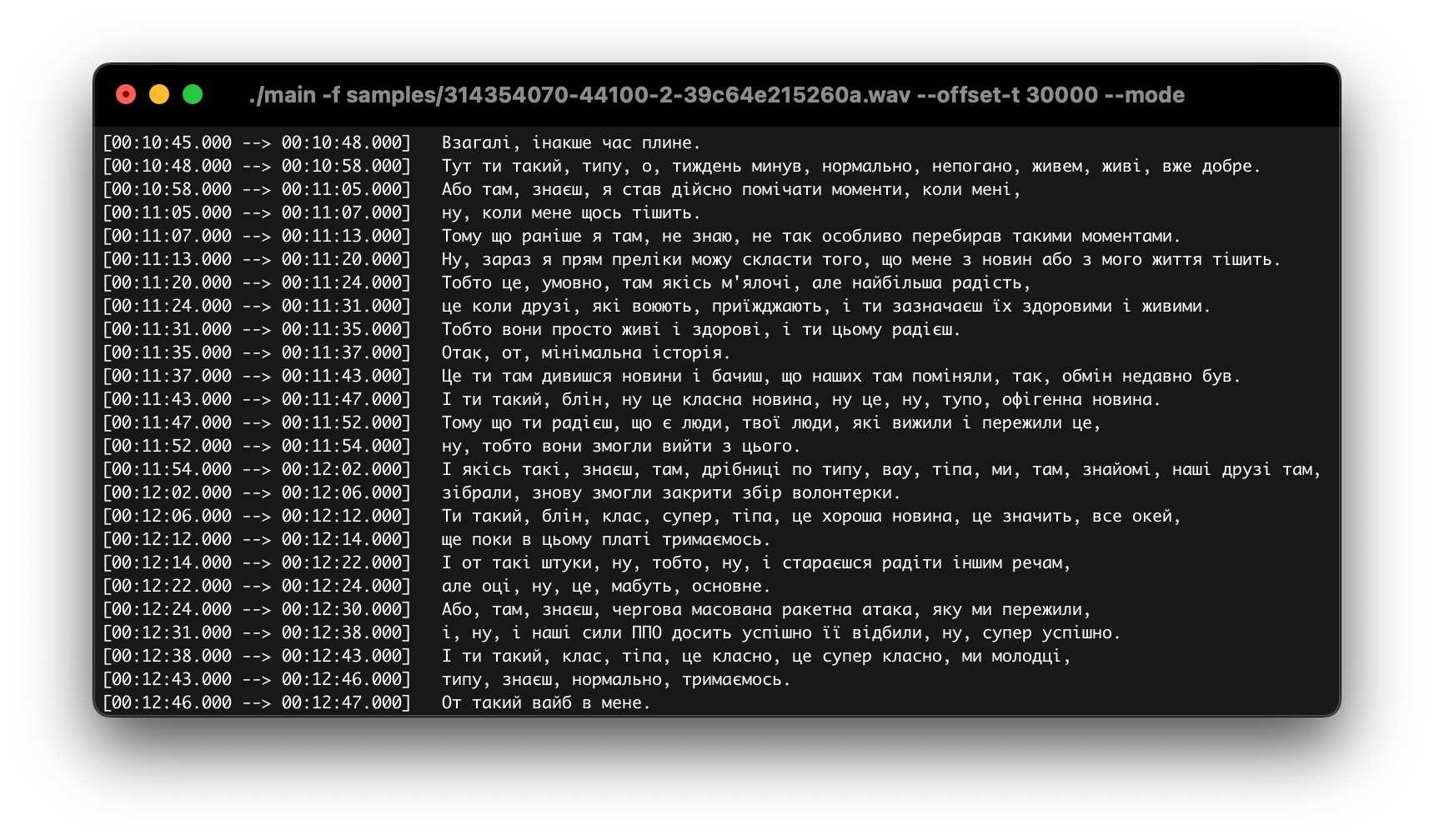
Тепер не потрібно буде воєнних експертів на ютубі дивитись – їх тепер можна буде читати! А з chatgpt можна взагалі буде попросити саммарі зробити, або навіть генерувати новий випуск подкасту на основі попередніх – буде така собі альтернатива подкастів з podcast.ai, які навчили нейронну мережу на основі біографії Джобса, нарізали голоси (на HackerNews в коментах автор розповідає за це), і вийшов досить цікавий подкаст
Модерація контенту
Іншою потенційно цікавою моделлю я побачив інструменти для модерації контенту. Перевіряти будь-який текст можна безкоштовно, і OpenAI повертає інформацію, чи знайшов він в тексті щось, що порушує їх політику – хейтспіч/образливі фрази та т.д.
OpenAI зазначає, що він поки що адекватно працює лише для англійської, тому фразу «Вова, їбаш їх блядь!» він позначив як безпечну, а от «Русні пизда!» вважає хейт-спічом. Ох, як же добре, що у мене блог не на якомусь фейсбучику або твіттері, і блокувати мене нікому!

Виглядає, як дуже прекрасний інструмент для модерації контенту будь-де — починаючи телеграм-ботами, закінчуючи тими ж ЗМІ.
Звісно, для наших реалій потрібно вводити категорії, як культура скасування/срач/шакалячий експрес/політота, але є надія, що з часом це вплине на якість коментарів, і модель покращать токсичними даними – у нас вони генеруються щоденно :).
Ще щось?
У них є досить багато прикладів, тому от раджу хоча б погратись з ним – може вийде щось досить корисне! OpenAI дає $18 кредиту на перші три місяці використання API, тому їх повинно вистачити абсолютно для будь-яких цілей. До того ж ціни за запити в OpenAI досить демократичні (і я приємно здивований).
На жаль, є трохи незручний момент з токенами – це одиниця виміру інформації в openai. Якщо в подкастах одиниця – це кількість секунд (тому кошти стягуються в залежності від часу) то для chatgpt-штук це – кількість літер. З англійською все ідеально (там 1 слово, як правило, приблизно 0.75 токенів – у фразі «Hello how are you» лише 4 токени), а от з кирилицею це проблема – 1 літера може займати 1-2 токени (наприклад у фразу «Привіт як у тебе справи» аж 27 токенів). У них є калькулятор кількості токенів, тому можна вставити будь-який текст та подивитись – в досить великих масштабах це буде дуже суттєво впливати :). До речі, саме токенізація і є причиною, чому в запитах англійською в вебінтерфейсі того ж ChatGPT відповідь друкується по слову, а українською – по літері.
Що далі?
Залишилось вижити не лише у війні, а у цьому світі контенту/відгуків/подкастів/відео/тіктоків/постів/пабліків, згенерованих за допомогою AI!
Головне – не будувати щопопало.ai :)
Люди в продуктових компаніях такі «ми маємо вирішувати реальні проблеми користувачів», а потім такі «опа у чатжпт є апішка, терміново додаємо і ПРИДУМУЄМО ЦЕЙ ФІЧІ НАЗВУ З ‘AI’ НАПРИКІНЦІ 🤡🤡🤡
— Stanislav Govorukhin 🇺🇦 (@_govorukhin) March 4, 2023